






Ausgabe 96/4, 31. Dez. 1996
Universitätsbibliothek der Technischen Universität Braunschweig, Universitätsplatz 1, D-38106 Braunschweig, Tel. (0531)391-5011, -5026, FAX -5836A web is spun, so large, so wide,
it wraps around the Earth.
What now,
and How?
Where does the mighty spider hide?
And what's this planet worth?
Immer einfacher sollen die Zugänge zu Datenspeichern werden, immer offener die Systeme, die sie verwalten. Ein Paradebeispiel für die Einstellung, mit der zunehmend Software beurteilt wird, ist eine Werbeanzeige, in der vor Jahren dem Fußballkaiser Franz Beckenbauer die Worte in den Mund gelegt wurden: "Ich brauche nicht zu wissen, wie es funktioniert, ich muß mich darauf verlassen können, daß es funktioniert." (Er soll sich damals bald davon distanziert haben, weil man das ja auch so verstehen konnte, als habe er wenig technischen Sachverstand.) Mit einer solchen Haltung ganz offen als Kunde gegenüber einem Anbieter aufzutreten, empfiehlt sich in der Tat wenig: man fordert es geradezu heraus, übervorteilt zu werden. Dennoch verbreitet sich die Sichtweise, daß Computer samt Software Maschinen sind wie andere auch, und daß ja auch niemand wissen müsse, wie der CD-Player funktioniert oder die Mikrowelle, um das Gerät benutzen zu können. Gebrauchsanweisungen sind als Lektüre unbeliebt. Das gilt für Elektrogeräte genauso wie für Softwaresysteme. Die latente, oft uneingestandene Erwartung, daß "alles" ganz einfach gemacht werden könne, wurde durch nichts anderes so augenscheinlich bestätigt und nachhaltig gefördert wie durch die "Point-and-click"-Methodik der Windows-Welt und ganz besonders die Funktionsweise der WWW- "Browser", Mosaic, Netscape, Internet Explorer etc. Die neue Vielfalt der Angebote wird durch die neue Einheit der Benutzungsoberfläche überhaupt erst handhabbar. Befehlsorientiertes Arbeiten (telnet, ftp etc.) wird vollends ersetzt durch Drucktastenbetätigung, Menüauswahl und Formulareingabe. Noch hat die Maus zwar Feinde, aber deren Zahl ist höchstens so groß wie die der schnellen Tastenschreiber, welche keine Mehrheit bilden. (Schreiben muß man momentan noch auf den Tasten, aber die Spracheingabe ist im Kommen.)
Über die gegenwärtigen Trends der DV-Industrie und ihre Auswirkungen kann man konträre Ansichten vertreten. Man mag im Web die Befreiung aus archaischen und bürokratischen Zwängen erblicken, ein Betätigungsfeld für das Streben nach Selbstverwirklichung, oder gar das Heraufdämmern der wahren Demokratie, man mag andererseits den drohenden Schwund von Qualitätsmaßstäben und den Verfall der Achtung vor geistigem Eigentum beklagen, vor neuen Gefahren der Überflutung warnen (Gedrucktes wird zweitrangig, weil weiter als einen Mausclick entfernt - wer hat dafür noch Zeit?), als Konsequenz eine neue Oberflächlichkeit (Schwieriges hat keine Chance mehr) oder gar platte Anarchie an die Wand malen, man mag spekulieren über eine neue Unmündigkeit vieler, die nichts mehr wirklich beherrschen und mangels technischen Durchblicks kritikunfähig zu grob falschen Erwartungen neigen, man mag letztlich nüchtern das Verkümmern des WWW zu einer WeltWeiten Wartegemeinschaft prognostizieren. Die allegro news sind bekanntlich kein Organ fürKulturkritik. Sie können nur bekannt machen, for better or worse, wie man allegro-Datenbanken für Leistungen im Web aufschließen kann. Und dazu soll auch diese Ausgabe wieder Beiträge leisten.
Web-Anwendungen bestechen zwar durch die Einfachheit ihrer Benutzung, unter der Oberfläche jedoch laufen durchaus komplizierte Vorgänge ab, wovon der "Surfer" so wenig sieht wie der Autofahrer von den Vorgängen im ABS oder im Turbo-Einspritzsystem - er tritt nur auf Bremse und Gas. Bei Problemen ist er aber auf den Spezialisten angewiesen, und genauso kann keine Web- Anwendung ohne SystemverwalterIn auskommen, denn es sind Komponenten notwendig, die sich nicht von selbst installieren und konfigurieren. Inzwischen laufen etliche allegro-Anwendungen im Web, die als Beispiele dienen können. Wer auf diesem Gebiet am Anfang steht, muß sich aber zuerst einen Überblick verschaffen. In dieser Nummer wird deshalb zusammengestellt, was man braucht und was manwissen oder kennen muß, um brauchbare Anwendungen mit Zugriffen auf eine allegro-Datenbank zu erstellen. Es handelt sich hier um Client/Server-Anwendungen, während die konventionellen Programme (PRESTO, SRCH, UPDATE etc.) alle unmittelbar auf eine Datenbank zugreifen und zugleich eine Benutzungsoberfläche enthalten. PRESTO-W, das Windows-PRESTO, arbeitet ebenfalls direkt und nicht mit dem avanti-Server zusammen. In tieferen Schichten der Programme bauen freilich beide auf denselben "Klassen" in der Programmiersprache C++ auf, aber PRESTO-W ist monolithisch (ein einzelnes, eigenständiges Programm) während WWW-Anwendungen immer aus mehreren Programmen bestehen, die arbeitsteilig zusammenwirken müssen (s.S. 2ff). Warum wird nicht gleich alles konsequent nach dem modernen Client/Server-Konzept konstruiert? Nun, auf Einzelplatzsystemen und kleinen lokalen Netzen ist dieses unnötig umständlich und deshalblangsamer. Viele auf Leistung bedachte Anwender werden auch weiterhin nicht unter Windows, UNIX oder mit dem Web arbeiten, sondern mit den DOS-Programmen, weil deren Leistung in wichtigen Aspekten unter graphischen Oberflächen und in Client/Server-Methodik nicht erreicht werden kann. 96/4 allegro news Nr.44 Andere werden vorerst einfach deshalb bei DOS und Novell bleiben, weil sie gar nichts andereshaben. Abgesehen von der oftmals fehlenden systemtechnischen Betreuung darf man nicht vergessen, daß Bibliotheken in aller Regel unterkapitalisiert sind und sehr viele mit Rechnern arbeiten, die "älter" als zwei Jahre sind - ohne Hoffnung auf baldigen Ersatz. Solche Rechner sind für Windows '95, Netscape etc. ungeeignet. Und Internet-Anschluß ist bei über 50% der allegro-Anwender noch nicht vorhanden und bei vielen auch mittelfristig nicht in Aussicht. Einige Programme, vor allem INDEX und SRCH sowie aLF und ORDER können vorläufig noch nicht durch neue ersetzt werden. Aus diesen Fakten ergibt sich, daß Pflege und weitere Verbesserung der konventionellen DOS- und UNIX- Programme weiterhin notwendig sind. Da jedoch Bibliotheken grundsätzlich immer mehr auf Zusammenarbeit, Austausch und weltweite Nutzung von Ressourcen angewiesen sind, ist die Hinwendung zu Netzanwendungen und zu den Standards der Internet- und Intranet-Welt auch so etwas wie eineÜberlebensfrage. Für Bibliotheken, aber auch für allegro.
Das folgende Diagramm zeigt in vereinfachter Form, wie eine Web-Anbindung strukturiert ist. So oder ähnlich sieht das Verfahren auch für andere Systeme aus, es ist nicht allegro-spezifisch. Alles gilt natürlich genauso für ein Intranet, d.h. ein hausinternes Internet innerhalb einer Institution. Daher sind diese Dinge nicht nur für Web-Angehörige interessant. Zum besseren Verständnis für Uneingeweihte: "Server" und "Client" sind Programme, also Software. In PC-Netzen bezeichnet man meist den zentralen Rechner (also die Hardware) als "Server" oder "File Server". Dieser wird hier "Host-Rechner" genannt. Auf ihm können neben Web-Server und avanti-Server gleichzeitig noch ganz andere Dinge laufen. Vielleicht das größte Problem ist, daß man mindestens vier verschiedene Sprachen sprechen muß: HTML, Perl, avanti, allegro-Exportsprache. Das Diagramm zeigt, wo welche Sprache zum Einsatz kommt.Die Nummern am linken Rand verweisen auf Abschnitte der nachfolgenden Beschreibung der diversen Vorgänge und Komponenten.

Beschreibung der Abläufe. Wir gehen von der Endstation aus, d.h. vom Bildschirm des "Surfers", der mittels Internet Explorer oder Netscape das Internet benutzt. Wir beschreiben im Einzelnen die Voraussetzungen, die gegeben sein müssen, die Kenntnisse, die jeweils gebraucht werden, und die dabei einsetzbaren Hilfsmittel. Ferner wird angegeben, welche Dateien des Beispielpakets man sich anschauen sollte oder als Muster für eigene Entwicklungen verwenden kann. (Das Beispielpaket ist unter dem Namen acwww25.exe auf dem FTP-Server im Verzeichnis anwender zu finden. Es ist ein "selbstentpackendes Archiv" und enthält den Text acwww25.txt mit einer detaillierten Anleitung.) Kenntnis der Web-Grundbegriffe setzen wir voraus, denn dazu gibt es genügend Literatur auf jedem Niveau.
Vom Konzept her völlig anders als eine WWW-Anbindung ist die Kommunikation zwischen Datenbanken mit dem Protokoll Z39.50, obwohl auch diese über das Internet laufen kann. Hier spielt HTML eine untergeordnete Rolle (höchstens auf der Client-Seite kommt es zum Einsatz), denn der Verkehr über das Netz findet mit einem eigenen Protokoll statt, eben Z39.50 und nicht http. Ein System mit solcher Schnittstelle ist in der Lage, mit anderen Systemen, die ebenfalls Z39.50 "können", sich über das Netz auszutauschen. Für den Endbenutzer sieht das so aus: Im Vordergrund steht immer die ganz normale Arbeit mit dem eigenen System; eine Abfrage, die am eigenen System erfolglos war, kann per Knopfdruck an andere Systeme weitergeleitet werden. Die Z39.50-Schnittstelle wandelt die Abfrage in eine standardisierte Form um und sendet sie an das oder die gewünschten Systeme. Diese nehmen die Abfrage entgegen, übersetzen sie in ihre eigene Abfragesprache, ermitteln das Ergebnis und senden dieses, wiederum standardisiert, an das System des Endbenutzers. Diesem wird es so präsentiert, als käme es aus dem eigenen System. Schematisch sieht das so aus. HOST-Rechner PC oder UNIX-Terminal im lokalen Netz
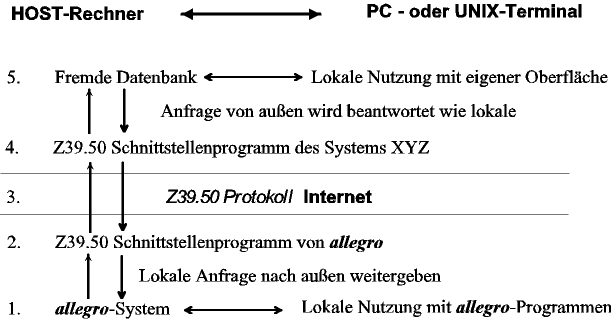
Man darf sich das etwa so vorstellen wie das Telefonieren mit dem (noch utopischen) simultan übersetzenden Telefon. Dieses Telefon übersetzt die Worte des Anrufers in Esperanto, und das Telefon des angerufenen Teilnehmers am anderen Ende übersetzt Esperanto in dessen eigene Sprache. So kann man (rein theoretisch) mit jedem Teilnehmer auf dem Planeten telefonieren, falls dieser auch ein solches Telefon hat. Es müssen also "nur" die Übersetzungsprogramme zwischen jeder gebräuchlichen Sprache und Esperanto geschrieben werden, nicht etwa Programme zwischen jeder Sprache und jeder anderen Sprache. Z39.50 spielt die Rolle eines Esperanto für Datenbanksysteme. Allerdings ist Z39.50 keine ganz einfache Sprache und entfaltet sich derzeit noch weiter. Es verfügt über eine große Zahl von Befehlen und Optionen, da es nicht nur für Katalogsysteme einsetzbar sein soll, sondern für Datenbanken in möglichst allgemeinem Sinne. Die Programmierung einer Z39.50-Schnittstelle ist deshalb, trotz Hilfssoftware, die es dafür gibt, ein recht umfängliches Unterfangen. Ziel der gegenwärtig laufenden Entwicklungsarbeit (unterstützt von der DFG) ist es, die Software dann nicht nur auf UNIX, sondern auch auf Windows-NT als Serversystem einsetzen zu können.
Es ist leicht zu sehen, daß diese Verfahrensweise völlig symmetrisch ist: Anrufer und Angerufener können sofort die Rollen tauschen. Wenn das eigene System eine Anfrage an ein anderes stellt, wird es als "Origin" bezeichnet, das Zielsystem wird "Target" genannt. Idealerweise soll aber jedes System beide Rollen spielen können.
Die Sprache Esperanto hat einen bekannten Nachteil: sie "lebt" nicht in derselben Weise wie natürliche Sprachen, weil sie nirgends als Umgangssprache fungiert. Die Idiomatik, Nebenbedeutungen, Stimmungen, Untertöne, ungeschriebene Regeln einer Sprechergemeinschaft, alles das "kommt nicht rüber", wenn ein Text über Esperanto als Zwischenstation übermittelt wird, und nicht immer gibt es überhaupt einen wirklich gleichwertigen Ausdruck, weder in Esperanto noch in der Zielsprache. Das Konzept Z39.50 krankt am selben Syndrom: Befehle, die mein System kennt, aber das Zielsystem nicht, kann Z39.50 nicht "rüberbringen", d.h. es kommt nichts dabei heraus. Wenn mein System ein Schlagwortregister hat, das Zielsystem aber nicht, erhalte ich kein Ergebnis. Und wenn mein System deutsche Schlagwörter hat, das Zielsystem aber englische, dann müßte tatsächlich eine echte Übersetzung stattfinden. Das jedoch kann Z39.50 nicht leisten. Wie das simultan übersetzende Telefon ist dies reine Utopie. Am besten wird Z39.50 funktionieren für ganz präzise Abfragen, z.B. nach einer ISBN, am wenigsten für thematische Anfragen.
Die nachfolgende Liste findet sich, etwas verändert, auch im neuesten Handbuch. Sie wird hier abgedruckt, weil sie vermutlich auch solchen Anwendern nützen kann, die sich das Handbuch (noch) nicht anschaffen konnten.
Für 1997 sind zwei Auslieferungen in der Planung: (mit dieser Nummer wird noch keine Diskette ausgeliefert!)
Jeder Abonnent erhält ein individuelles Passwort und eine Benutzernummer. Nur mit diesen Angaben können die Programme heruntergeladen werden, während der Katalog mit APAC frei benutzbar sein wird. Ohne Paßwort wird die CD zu einem niedrigen Preis für jedermann erhältlich sein und damit auch als Demo-Disk dienen können. Wer kein CD-Laufwerk hat, kann nur die Programme auf Diskette bekommen.
Wenn ein Stammsatz verlängert und die Ansetzungsform verändert wurde (z.B. Goethe, Johann W. geändert in Goethe, Johann Wolfgang), funktionierte das automatische Verlagern der Registereinträge nicht. Das wurde korrigiert am 7.11.96.
oder so gut wie. Man braucht sie bei PRESTO und UPDATE nicht mehr anzugeben. Die Programme merken es selbst, wenn sie nicht im Mehrplatzmodus arbeiten können und schalten auf Einzelplatzmodus. Die Option wurde nicht völlig abgeschafft, denn im Einzelplatz hat sie noch einen geringen Vorteil: der Start geht etwa eine Sekunde schneller (weil das Programm nicht erst prüft, ob Mehrplatzmodus möglich ist). Im Mehrplatzbetrieb darf man weiterhin -S nicht verwenden, weil dann zu einem Zeitpunkt nur einer arbeiten kann. Die Empfehlung lautet deshalb: lassen Sie ab V15 generell -S beim Start von PRESTO und UPDATE weg. Anmerkung: Man verwechsle die Option -S (= Single User) nicht mit dem Flag S (= Sharable), das man bei Novell setzen muß, um den Mehrplatzbetrieb überhaupt zu ermöglichen (Befehl flag *.* s auf dem Datenverzeichnis). Als Nebenwirkung hat sich ergeben, daß man das Flag S jetzt sogar vergessen darf. Der Anlaß zur Abschaffung (erfolgt am 19.12.96) war eigentlich der folgende:
Gelegentlich passierte es, daß PRESTO oder UPDATE im Einzelplatzbetrieb ohne die Option -S gestartet wurde. Man merkt sehr bald, daß etwas nicht stimmt, weil das Abspeichern eines Satzes viel länger dauert als normal. Der Satz wird dann zwar gespeichert, aber die Registereinträge nicht. Bei Neu-Indexierung wurden solche Sätze dann doch noch sichtbar. Erst am 28.11.96 wurde entdeckt, daß durch vergessenes -S auch etwas ganz Unerfreuliches passieren konnte: ein Satz konnte völlig verschwinden, oder es entstand eine falsche Adresse in der .TBL-Datei (Fehlermeldung kein Eintrag unter dieser Satznummer ODER fehlerhafte Satznummer), oder am Ende eines Datensatzes hingen plötzlich Kategorien eines anderen Satzes. Diese Fehler entstanden als Folgewirkung, weil die vergessene Option -S auch die korrekte Verwaltung der "Leerschlüssel" (unter // im Register 1) verhinderte. Diese Probleme können in den aktuellen Programmen nicht mehr auftreten.
Wenn eine Datenbank vollständig erneuert wird ("Routinen / Organisieren / 7 oder n") werden jetzt die alten Datenbankdateien nicht mehr gelöscht. Sie werden nur umbenannt: als CAT_1.ALD wird CAT_1.A1D. Ist etwas falsch gelaufen, z.B. durch Stromausfall während des Indexierens oder weil die Platte überlief, hat man die intakten Ausgangsdateien noch vorliegen. Man löscht die neuen (Typ .ALD), nennt die alten wieder auf .ALD um, und startet den Vorgang neu. Das hat zur Folge, daß bei erneutem Versuch eines Neuaufbaues die Meldung kommt: Dateien vom Typ .A1D zuerst prüfen / Check Files of Type .A1D first Wenn man sicher ist, daß die alten Dateien wirklich nicht mehr benötigt werden, kann man sie jederzeit löschen. Bei großen Datenbanken sollte man das auch unbedingt tun, weil dadurch vielPlatz belegt wird. Der Neuaufbau wird jedenfalls erst dann durchgeführt, wenn man die alten Dateien gelöscht oder umbenannt hat. Dazu gibt es unter "Organisieren" den neuen Menüpunkt "a = Altdateien (.c1D) löschen". Tun Sie das im Normalfall, nachdem ein Neuaufbau erfolgreich stattgefunden hat.
Das CockPit startet jetzt automatisch die zweistufige Indexierung mit -@1 und -@2 -fi1, wenn die Datenbank mit V14-Ersetzungen arbeitet. Diese Tatsache erkennt das CockPit an dem Befehl i5 in den Indexparametern, der nur dann vorkommt. Die zweistufige Indexierung geht schneller als die andere Methode, bei der QRIX automatisch am Ende nochmals INDEX für einen zweiten Durchlauf aufruft, um die Ersetzungen im Index durchzuführen. Diese Methode funktioniert allerdings weiterhin, wenn man INDEX mit der Hand oder aus einem Batch heraus aufruft. Genau gesagt: QRIX startet trotzdem den zweiten Durchlauf (INDEX -fa1), denn es könnten noch unerledigte Ersetzungen vorkommen. Wichtig für die zweistufige Indexierung: in den Indexparametern innerhalb des Abschnitts #-@ fürden Primärschlüssel keine Besetzungen von Variablen vornehmen, die sich anschließend in anderen Abschnitten auswirken sollen. Denn im zweiten Durchlauf mit -@2 hat INDEX diese Variablen dann nicht zur Verfügung, weil der Abschnitt #-@ dann nicht ausgeführt wird. Bauen Sie solche Variablenbesetzungen z.B. in den Abschnitt #-0 für die Kurzanzeige ein und sorgen Sie dafür, daß dieser Abschnitt ausgeführt wird, bevor die Variablen gebraucht werden.
Mit der Option -Qdateiname kann man vorgeben, in welche Datei die Protokollzeilen zu schreiben sind. Als Standard wird die Datei protoq genommen. Wichtig kann das sein, wenn man auf demselbenVerzeichnis zwei Vorgänge mit QRIX startet.
Bisher konnte man in einem Exportbefehl nur Vergleiche mit vorgegebenen Zeichenketten oder Einzelzeichen anstellen. Und zwar wird der Manipulationsbefehl cX dazu benutzt. Wenn man z.B. schreibt:
#20 +A c"~berlin" e0
dann wird zur Sprungmarke #-A gesprungen, wenn "berlin" in beliebiger Schreibweise in Kategorie #20 vorkommt. Ein anderes Beispiel: mit dem Befehl
#90 c"[ABC]" p"Signatur: "
wird die Kategorie #90 genau dann ausgegeben (mit "Signatur" als Präfix), wenn sie einen der Buchstaben A, B oder C enthält. Sonderfall: wenn das Zeichen '[' vorkommen soll, muß man c"[[]" schreiben. Die Neuerung besteht darin, daß innerhalb der Anführungszeichen jetzt auch eine Kategorie vorkommen kann. Das sieht also z.B. so aus:
|
#31 +B c"#usw" e0 |
bzw. |
#31 +B c"#33" e0 |
Hier wird nach #-B gesprungen, wenn der Inhalt der Sonderkategorie #usw bzw. der Kategorie #33 innerhalb der Kategorie #31 vorkommt. Was aber, wenn man testen will, ob z.B. der Inhalt von #33 exakt gleich dem Inhalt von #31 ist? Das könnte man so machen:
|
#33 dsw p"QX" P"QY" dsw asw |
Kopiere #33 in #usw, aber mit "QX" davor und "QY" dahinter |
|
#31 +B p"QX P"QY" c"#usw" e0 |
Setze "QX" vor und "QY" hinter den Text von #31 und vergleiche mit #usw |
Man hängt also zuerst geeignete Prä- und Postfixe an, bevor man den Vergleich macht. Bei allen Beispielen muß man #zz 0 anhängen, wenn der Parameter ke benutzt wird, weil man sonst unerwünschte Postfixe bekommt.
Weitere Möglichkeiten
Im Handbuch (S.210, Kap.10.2.6.7) fehlt die Beschreibung einer wichtigen zusätzlichen Möglichkeit. Wenn man nachladet, präpariert man ja zuerst einen Arbeitstext xyz, der dann in einem Register gesucht werden soll. Es wird der erste Satz, oder der erste Schlüssel, geladen, der mit xyz übereinstimmt oder mit xyz anfängt, je nach Modus des Nachladens. Will man aber auf denjenigen Schlüssel zugreifen, der unmittelbar vor oder hinter xyz kommt, so kann man das erreichen, indem man als Präfix vor den Arbeitstext das Zeichen '<' bzw. '>' setzt. Beispiel:
#dt p"<mueller!" e"!" |18
Wirkung: lade aus Register 1 den Schlüssel (d.h. den Namen), der unmittelbar vor "mueller" kommt. Dieser Schlüssel wird in die Variable #ux1 kopiert. Bei Modus 0 statt 8 würde der zugehörige Datensatz nachgeladen.
Wenn man bei der Druckaufbereitung die Anzahl der schon produzierten Zeilen braucht, kann dazu eine der drei folgenden Sonderkategorien benutzt werden:
|
#pz0 |
Nummer der aktuellen Zeile, auf der gerade gedruckt wird (beginnend bei 1) |
|
#pz1 |
Anzahl insgesamt produzierter Zeilen für den aktuellen Datensatz |
|
#pz2 |
Anzahl bereits erzeugter Zeilen auf der aktuellen Seite (wenn zm >0 ist) |
Es kommt vor, daß man mit dem Befehl txy eine Tabellendatei xy.apt hinzuladen will. Bisher monierten die Programme nichts, wenn diese Datei nicht gefunden wurde. Jetzt bekommt man die Fehlermeldung "Datei xy.apt existiert nicht" und das Programm wartet, daß man eine Taste drückt zur Bestätigung der Kenntnisnahme. Dieser Mangel konnte ärgerlichen Zeitverlust verursachen, denn man mußte ja erst drauf kommen, daß ein Export deswegen nicht klappte, weil der Name der Tabelle falsch angegeben war oder sie gar nicht vorlag.
Manchmal werden ohne erkennbaren Grund bestimmte Registereinträge nicht erzeugt. (Schon in Nr. 40, S.9, wurde darauf hingewiesen!) Die Ursache kann ein zu knapp eingestellter Hintergrundspeicher sein. Wenn dieser durch die Bearbeitung einiger sehr langer Datensätze voll gelaufen ist, können keine Anwendervariablen (#u-Kategorien) mehr gespeichert werden. In vielen Indexparametern wird aber von solchen Variablen Gebrauch gemacht, um bestimmte Einträge zu produzieren, und diese entstehen dann nicht. Abhilfe: man prüfe nach mehreren Eingaben oder Bearbeitungen mit Alt+F7, ob diese Situation wirklich vorliegt. Wenn ja, muß man den Wert mB in der CFG heraufsetzen. Standardmäßig ist mB12000 eingestellt. Dies reicht fast immer aus. Es kann aber auch sein, daß man in den Anzeige- oder Indexparametern eine Variable nicht korrekt löschen läßt, so daß diese immer länger wird. Mit demBefehl #au im Editor kann man solche Variablen aufspüren.
Das Testen von Exportparametern kann zermürbend sein. Abhilfe bringt für viele Fälle der Manipulationsbefehl ! . Er bewirkt, daß an dieser Stelle angehalten und der aktuelle Arbeitstext am Bildschirm gezeigt wird. Einsetzbar ist dies natürlich vorwiegend in solchen Parametern, die man am Bildschirm testen kann (siehe Kap.10.3). Man schreibt z.B.
#98 b"abc" ,"_def_ghi_" p"jkl" ! P"mnq"
Dann wird unmittelbar vor dem Anhängen des Postfixes "mnq" der Arbeitstext gezeigt. Man sieht in diesem Fall, ob die lokale Ersetzung auch funktioniert hat. Gerade die Ersetzungen können einen Exportbefehl unübersichtlich machen. Dann schafft ! mit einem Mal Klarheit.
Die lokalen Ersetzungen (Kap. 11.2.3.4) waren problematisch, wenn dabei Felder verlängert wurden. Es konnten dann nachfolgende Felder verschwinden (nicht mehr gefunden werden). Diese Mängel sind behoben.
Mit einer der V14-Varianten war es eingeführt worden (und zwar in Verbindung mit dem Manipulationsbefehl M), daß die Eingabe einer leeren Kategorie zu deren Löschung führte, falls sie im aktuellen Satz besetzt war. Kurz: man gab z.B. #71 <Enter> und #71 verschwand, wenn sie besetzt war. Das wurde jedoch nicht in irgendeiner Weise angezeigt, fiel also u.U. gar nicht auf. Diese Funktionsweise wurde deshalb zum "Misfeature" erklärt und wieder beseitigt. Das Löschen von Kategorien geht also weiterhin nur mit dem Befehl #v, d.h. um #71 zu löschen, muß man #v71 <Enter> eingeben. Innerhalb des Fensters beim Befehl #b ist es anders: Wenn eine Kategorie im Fenster auftaucht, kann man sie löschen, indem man den gesamten Text, aber nicht die Nummer, beseitigt. Danach kommt dann leider die übernächste Kategorie zum Vorschein, aber mit F9 kann man zu der übergangenen zurück. Nichts geschieht, wenn man das Fenster völlig leer macht oder nur das Promptzeichen stehenläßt.
Im Ablauf der Abfrageliste konnte es irritierende Erscheinungen geben. Scheinbar war die Abfrage vorzeitig zu Ende, bei Druck auf <Enter> ging's jedoch weiter. Auch die Sprünge waren manchmal unzuverlässig. Diese Probleme wurden endlich beseitigt, nachdem daran lange laboriert worden war. Die Abfrageliste darf nicht mit einer Sprungmarke enden. Programmintern ist das Abarbeiten der Abfrageliste ein erstaunlich kompliziertes Problem. Im Grunde liegt es daran, daß hier wie kaum sonst irgendwo die künstliche Intelligenz des Rechners und die natürliche des Anwenders aufeinandertreffen. Das sind zwei ganz verschiedene Welten. Die Wünsche der Anwender sind zudem sehr vielfältig, zumal mit unterschiedlichsten Formaten gearbeitet wird. Der einzelne Anwender sieht meistens nur die eigenen Anforderungen, die aus der Sicht des Ganzen immer Spezialfälle sind. Eine Software, die speziell nur für ein bestimmtes Format gemacht wurde, kann völlig anders programmiert werden und für dieses spezielle Format dann natürlich besser sein als allegro.
Das schon recht alte Programm ASORT.EXE wurde geringfügig verbessert, so daß es auch ASCII- Textdateien jetzt in jedem Fall korrekt sortiert. Der Piepston am Ende wurde beseitigt. Ursprünglich wurde das Programm nur deswegen geschaffen, weil das zu MS-DOS gehörige Programm SORT nicht mit Dateien fertig wird, die größer als 64K sind und deren Sätze länger als 255 Zeichen sein können. Unter UNIX gibt es Programme, die nicht solche (blamablen) Grenzen haben. Hier ist besonders GNU-Sort zu nennen, das meistens unter dem Namen sort verfügbar ist. Für MS-DOS gibt es ein äquivalentes Programm. Um Verwechslungen zu vermeiden, nennen wir es GSORT. Der Aufruf muß so aussehen (bei UNIX sowohl wie MS-DOS):
gsort eingabedatei >ausgabedatei
Das Umlenkzeichen '>' ist leider wichtig, daher kann man nicht einfach GSORT.EXE auf ASORT.EXE kopieren. GSORT ist schneller als ASORT und hat eine Reihe von weitergehenden Möglichkeiten, die mittels Optionen anzugeben sind. Man entnimmt alles der Beschreibung GSORT.TXT (die "man page" von GNU- Sort), die auf dem FTP-Server zu finden ist. Das ganze Paket steht als SORT.LZH unter AC14/V14C/PROG auf dem FTP-Server.
Einziger Vorteil von ASORT: mit der Option -u kann man erreichen, daß die Kategorien #u1 und #u2 in der Ergebnisdatei nicht mehr vorhanden sind. Dies ist jedoch oft nicht erwünscht. Für SUN und LinuX wurde, obwohl es gsort gibt, dennoch ein asort erstellt.
Dieses beliebte Einfach-Ausleihprogramm (auf Basis von APAC) wurde auf der letzten Diskette erneut mitgeliefert. Seitdem wurden einige weitere Verbesserungen angebracht. Außerdem hat Herr Allers am Goethe-Institut die Parametrierung noch verbessert und die Verwaltung von Benutzerdaten eingebaut.Die Dateien dazu liegen unter ALFAHA.LZH auf AC14/V14C/PROG. Diese Datei enthält eine ausführliche Darlegung von Herrn Allers und eine Demo-Datenbank. Das gleiche Paket werden wir auf der angekündigten CD mit ausliefern. In ganz knapper Form hier die entscheidenden Tastenfunktionen: (alles auf dem Anzeigeschirm, wobei der auszuleihende Titel in der Anzeige steht)
|
TAB |
Ausleihe bzw. Rücknahme |
<Alt>+F10 |
Umschalten zwischen Ausleihe/Rücknahme |
|
I |
Kurzaufnahme (Eingabemaske) |
X |
Hinzufügen eines Exemplars (Signatureingabe) |
|
<Alt>+k (im Entleiher-Eingabefeld) |
Wiederholung des letzten Entleihers (neu ab Dez.96 !) |
||
Mit find #satznummern kann man eine Folge von internen Satznummern, getrennt durch Kommas, dem find-Befehl übergeben. Diese Nummern werden dann zur aktuellen Ergebnismenge ergänzt. Man setzt dies ein, wenn man vorher mit dem qrix-Befehl oder mit list i eine Folge von internen Satznummern gewonnen hat. So kann die Ergebnismenge ohne Indexzugriff erstellt werden. In den WWW-Anwendungen wird das ausgenutzt. Damit man vom qrix-Befehl das richtige Resultat bekommt, muß man zuerst die Einstellung qrix f 1 vornehmen. Mit qrix n anz kann man außerdem die maximale Trefferzahl je Registerzeile begrenzen. Die Ergebniszeilen haben dann die Form anzahlTABregistereintragungTABnummer1:nummer2:...:letzteNummer. Solche Ergebnisse kann man mit Perl oder anderer Software leicht auswerten.
Der Befehl switch coding schaltet die Umcodierung mittels der o-Tabelle (o.apt) für die write- Befehle ein. Dies wirkt sich auf alle write-Befehle aus, bis erneut switch coding gegeben wird.
Es haben sich mit der Zeit einige obsolete Dateien und Programme angesammelt, die bei einigen Anwendern vielleicht immer noch im Programmverzeichnis nutzlos herumliegen. Hier eine Liste derjenigen Dateien, die auf jeden Fall gelöscht werden können oder umbenannt werden sollten:
AKAT.EXE, AC.EXE veraltete Versionen von APAC.EXE
A.BAT sehr alter Vorgänger von CP.BAT (bevor es CockPit gab)
MENU.EXE sehr altes Startmenü-Programm (wird aus A.BAT aufgerufen)
Z*.EXE alte Programmversionen (umbenannt bei der Installation von V13)
ACPS.BAT jüngerer Vorgänger von CP.BAT. Wenn Sie noch immer mit dem Befehl acps starten, machen Sie folgendes: copy acps.bat cp.bat und copy default.opt cp.opt. Dann Aufruf nur noch mit cp .
DEFAULT.OPT alte Vorgabendatei, ersetzt durch CP.OPT. Siehe ACPS.BAT
A.CFG kann gelöscht werden, wenn es $A.CFG gibt, denn die Programme nehmen dann automatisch die letztere. Dasselbe gilt für P.CFG, wenn es $P.CFG gibt, usw. S.CFG, V.CFG alte Konfigurationen (Südwestverbund, Videodaten), die nicht von Braunschweig unterstützt werden. Löschen, falls man nicht mit einer davon arbeitet. Zugehörige Parameter *.SP? und *.VP? gleichfalls.
KAT.API alte Version von CAT.API. Wenn Ihre Datenbank schon mit CAT.API arbeitet, können Sie KAT.API löschen.
CIS.API, SPEZ.API, MPC.PPI, NZN.NPI, DK.API alte Indexparameter; löschen, falls nicht verwendet.
P1.APR, P1.SPR etc. alte Versionen von D-1.APR, D-1.SPR etc. Stellen Sie fest (Option -p in Ihren Batchdateien und Befehl p in CP.OPT), ob bei Ihnen noch P1.?PR benutzt wird. Dann ersetzen Sie in diesen Optionen P1 durch D-1 und kopieren Sie die P1.?PR in Ihr Datenverzeichnis auf den Namen D-1.
APR. P2.APR alte Parameterdatei für Listendruck. Nachfolger: P-*.APR PA.APR alte Version von I-1.APR. Wenn in einer Batchdatei noch so etwas wie -epa/datei steht, ändern Sie dieses auf -ei-1/datei und löschen Sie PA.APR.
PS.APR alte Sortier-Vorbereitungsdatei. Dürfte kaum noch irgendwo im Einsatz sein. Wurde ersetzt durch die Dateien vom Typ S-*.APR.
VGAFONT Unterverzeichnis (angehängt an C:\ALLEGRO) mit einer älteren Software für den Zeichensatz DIN 31628. *.FNT Diese Software wurde durch FONTLOAD und OSTWEST.FON sowie VGAN.FON ersetzt. Löschen Sie dieses gesamte Verzeichnis. Wenn in Ihren Batchdateien noch irgendwo VGAFONT aufgerufen wird, ersetzen Sie dies durch den Aufruf fontload <ostwest.fon und danach aw , wenn Sie die Hilfstabelle mit Alt+w haben möchten. Wenn VGAFONT.EXE und Dateien des Typs .FNT auf C:\ALLEGRO liegen: auch löschen.
SWITCH.EXE altes Hilfsprogramm, gehörte zu VGAFONT. Löschen, Aufrufe in Batchdateien beseitigen.
USE.BAT, ACCESS.BAT, CREATE.BAT, SELECT.BAT, PSELECT.BAT Batchdateien aus der Zeit vor CockPit.
Manche Sachen findet man nur in den news, außerdem stellen diese eine Chronologie der Entwicklung dar. Es gibt außerdem eine Datenbank, in der man natürlich auch nach Stichwörtern suchen kann, und eine andere mit vielen Tips und Tricks, die nicht alle in den news standen (auf dem FTP-Server)
Die im Original hier abgedruckte Inhaltsübersicht finden Sie in diesem HTML-Kontext in schönerer Form.
Immer wieder wird bedauert oder moniert, daß die allegro-Entwicklungsabteilung keine Unterstützung vor Ort oder in der Region leisten kann. Es ist zwar fast jedem klar, daß personalintensive Dienstleistungen nicht in den geringen Entgelten für das Abonnement enthalten sein können, manchmal wurde aber tatsächlich schon angerufen, wann denn jemand komme, um das System zu installieren und das Personal zu schulen... Grundsätzlich bieten sich zwei Wege aus dem Dilemma an:
Denkbar (aber noch nirgends realisiert) ist ein Modell, wobei mit begrenztem finanziellen Beitrag (deutlich mehr jedoch als die Abonnementkosten) die Bibliothek Zugang zu den fachlichen Supportleistungen (Installation, Schulung, ad- hoc-Unterstützung) einer Art Fachstelle erhält. Wo diese Fachstelle angesiedelt oder eingebunden sein soll, wie sie betrieben werden kann (Kontinuität!), das ist alles nicht einfach zu lösen. Theoretisch könnte das für die einzelnen Einrichtungen viel billiger sein als eine individuelle Betreuung durch eine Firma. Praktisch steht aber vor allem im Wege, daß die Bibliotheken nicht dem gleichen Unterhaltsträger angehören. Gedanken dazu hat sich der Kollege Robert Fischer in Berlin gemacht. Er hat zu dem Thema auch ein detailliertes Papier mit vielen Überlegungen erstellt und ist an diesbezüglichen Kontakten interessiert. (Landesbildstelle Berlin, Wikingerufer 7, 10555 Berlin). Herr Fischer hat auch einige sehr brauchbare Handreichungen und Schulungsmaterialien ausgearbeitet. Sachverstand vor Ort ist aber, auch wenn eine befriedigende Support-Lösung gefunden wird, in keinem Fall völlig verzichtbar. Ohne ein gewisses Problembewußtsein und grundlegende Kenntnisse kann niemand dem Supporter eine sinnvolle Frage stellen oder einen realisierbaren Wunsch formulieren. Weil das Systemhandbuch vielfach als zu schwere Kost empfunden wird (schauen Sie aber in das neue ruhig mal hinein!), gibt es in Bälde eine neue Einführung auf bewährter Grundlage:
Das allegro-Lehrbuch vom Kollegen Heinrich Allers ist vergriffen und kann leider nicht in absehbarer Zeit aktualisiert werden. Eine anerkannte Allegrologin, Frau Dr. Annemarie Tews in Leipzig, hat es dankenswerterweise übernommen, die beliebte Ouvertüre zu überarbeiten, zu ergänzen und zu aktualisieren. Eine äußerst wertvolle Ergänzung, die Frau Tews ausgearbeitet hat, ist ein umfassendes Glossar der allegro-Begriffe: abgestimmt mit der Entwicklungsabteilung ist hier eine Liste von knapp 200 Begriffen zusammengestellt und in konsistenter Weise erläutert worden. Hiermit soll Einsteigern wie erfahrenen Anwendern auch die Orientierung im Handbuch erleichtert werden, das durch die Ouvertüre jedoch nicht ersetzt werden kann. Die erweiterte Ouvertüre enthält neben dem bisherigen Text und dem Glossar auch eine Sammlung von Tabellen und Übersichten. Die gesamten Gebiete Parametrierung und Konfiguration werden jedoch nicht behandelt! Die alten Texte (WordPerfect und HTML) auf FTP bzw. WWW werden durch den neuen ersetzt, sobald er fertig ist. Eine spätere Buchveröffentlichung wird erwogen.
Verzögerungen bei der Fertigstellung des Erweiterungsbaues der UB Braunschweig haben es bewirkt, daß wir den für Ende Februar / Anfang März avisierten Termin verschieben mußten: das Treffen soll nun definitiv am 10./11. April stattfinden. Die bereits gemeldeten Teilnehmer erhalten in den nächsten Tagen ihre Anmeldeformulare. Noch ist die Veranstaltung nicht ausgebucht, die Teilnehmerzahl muß aber auf 50 begrenzt werden. Hier das (noch etwas vorläufige) Programm:
|
Termin |
Do./Fr. 10./11. April 1997 |
|
|
Ort |
Universitätsbibliothek Braunschweig, Universitätsplatz 1 (Postf. 3329, D-38023 Anfahrt: vom Hbf mit Bus 19 oder 29 bis Haltestelle "Pockelsstraße" (ca. 10 min.) |
|
|
Programm |
Donnerstag, 10. 4. |
|
|
|
11.00 - 12.30 |
Eversberg: Stand der Entwicklung, Vorstellung von V15 |
|
|
13.30 - 14.15 |
Evers: Allgemeines über Netzfragen, Web-Server etc. |
|
|
14.30 - 15.15 |
Veltkamp: Z39.50-Entwicklung |
|
|
15.30 - |
Eversberg/Höppner: Vorführung der Web-Dienste der UB, Endbenutzersicht |
|
|
19.00 - |
Gesprächsabend in der UB, mit Kaltem Büffet. Gelegenheiten zum Ausprobieren |
|
|
Freitag, 11. 4. |
|
|
|
9.00 - 10.30 |
Höppner: WWW-Methodik: Einsatz von "avanti" etc. |
|
|
11.00 - 12.00 |
Pfeiffer: neuere UNIX-Entwicklungen |
|
|
12.30 - 13.30 |
Mittagspause |
|
|
13.30 - |
Beiträge von Anwendern, Schlußdiskussion |
Um sich in die Liste einzutragen, senden Sie an die Adresse maiser@buch.biblio.etc.tu-bs.de nur diese Message: subscribe allegro . Und zum Abmelden: unsubscribe allegro .
© 1996 UB Braunschweig, Bernhard Eversberg (b.eversberg@tu-bs.de)
Fragen bitte an:
ub@tu-bs.de